
Leaving Wordpress
I’ve been using Wordpress for this blog since circa 2006 I believe, but as I mentioned in an earlier blog post that I was not 100% happy with using Wordpress for this blog. I have a few issues with Wordpress, none of them a major dealbreaker, but collectively enough to make me consider something else:
- the new Gutenberg editor set to become standard in 5.0 was in my experience, very clunky and kinda annoying
- the code structure of Wordpress is very deep and complex, sometimes making it difficult for me to make changes I want. I can usually figure it out, but it feels like things are unnecessarily more complicated than they need to be
- Wordpress’s rich plugin library is a plus, but it also means having to figure out how to have multiple plugins interoperate with each other. An easy example is that I was using a queueing plugin that didn’t work great with the Gutenberg editor
- Wordpress requires a lot of maintenance, including needing to regularly update plugins for security purposes, and comment moderation
Static Site Generators
At the same time, while reading across some blogs over the past few months, I had ran into the idea of static site generators, which intrigued me as a Wordpress alternative. SSGs offered several advantages:
- I could compose my posts offline and using any text editor I wanted, using a simple format like Markdown
- Page load performance is better since Apache will simply serve up the static files, no processing or database hits of any kind
- Static sites don’t require security updates of any sort - there’s no database or admin backend to be hacked
- Easy backups. In WP I was using a custom plugin for backups. With an SSG, I can simply have the raw content stored in Github, then the static content “built” from there. The content always exists in at least three places - the actual site, Github, and my local computer I use for posting.
Why Hugo
There’s quite a lot of static site generators available right now actually. The most popular one seems to be Jekyll which is ruby-based. I first decided to try Pelican because I preferred Python over Ruby. However, it turned out problematic on my Windows machine, I encountered some interoperability problems with pandoc for the WP migration. I didn’t want to have too many dependencies and issues with dependencies because I would later want to deploy the generator itself to my hosting on Webfaction for automated deployments, so I wanted the setup to be as easy as possible.
Then I stumbled upon Hugo, which offered two main advantages:
- the MSP was performance. I wanted to migrate over the entire history of the blog, which was almost 900 posts at this point.
- no external dependencies - all I needed was to download the hugo executable
After reading up and testing a bit of Hugo, I had a fit of “I couldn’t sleep, I’ll just go ahead and do the site migration now” that I would later regret since it completely screwed up my sleep schedule.
Wordpress Export
I used the Wordpress to Hugo plugin to convert my Wordpress content for Hugo. Many posts had reported problems with this plugin, but I didn’t have any issues with its basic operation. I had a two problems with it:
- when exporting existing Wordpress comments, it didn’t include the commenter’s URL, which I felt I should include
- all the posts were exported into a single
postsfolder. While this didn’t create any permalinks issues due to each post having theurlattribute in the frontmatter, it made the entire folder look very unorganized since I had almost 900+ posts. I preferred that the posts be grouped by year and month, matching the/yyyy/mm/slug/format of the permalink
Since I had the source for the plugin, it was straightforward to fix both issues myself.
After getting the export from the plugin, I still had a bit of post-processing and cleaning up of the posts to do.
For one thing, all the single-quotes in the exported posts seem to have been converted to HTML entities for that smart quote thing, so I had to reverse that. Luckily, it was a simple find and replace across text files. The format for embedding posts such as Twitter, Youtube, etc was different as well, I had to correct those files one by one.
Cleaning up the taxonomies
I had always wanted to clean up the categories in the blog, but I never got around to it with Wordpress because I didn’t feel like figuring out the SQL I would have needed to do it. (I’ve never liked Wordpress’s table structure.). With Hugo, all I had to do was update a bunch of text files, which I was much more comfortable with. This involved simply importing a Python library to parse frontmatter, and a script to do the conversion.
Generating the archive pages
Hugo doesn’t have built-in support for archive pages, so I had to create them myself. I followed the setup described in this blog post and wrote a python script to generate the individual year/month archive pages.
A bigger problem was the archive listing (the page that would link to the individual archive pages). Because the blog has been running for 15 years, there’s a whole lot, so I preferred to organize them in a table like this:
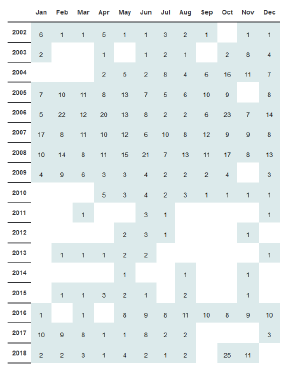
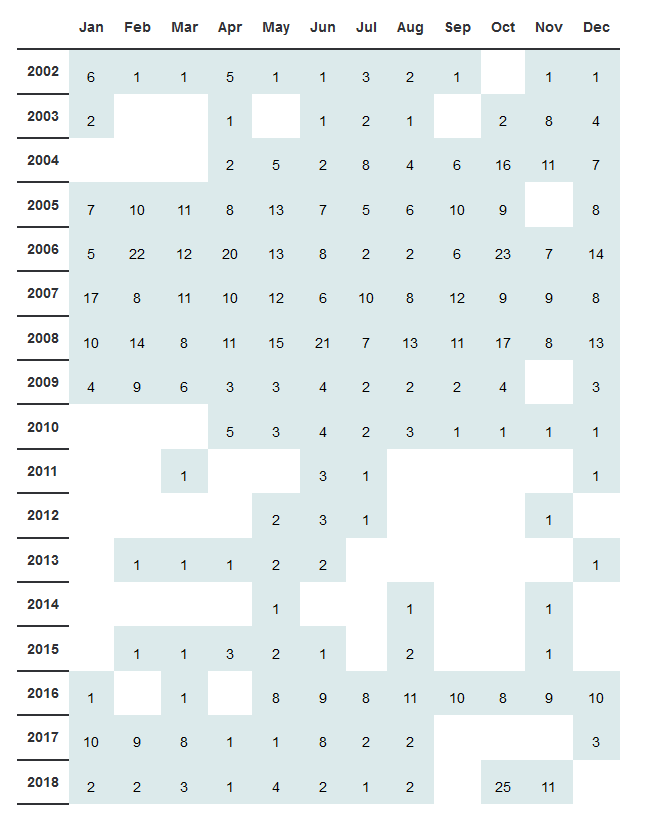
I actually couldn’t find a decent Wordpress plugin that did this for me exactly, so I wrote my own plugin for this.
For Hugo, I struggled with this a while and was close to figure out when I finally got the approach right. CHeck my archives page for how it turned out. The upside is I got to become a bit familiar with https://golang.org/, particularly the way content is parsed and processed in Hugo templates.
Custom shortcodes
I had some custom-formatted code in Wordpress that wasn’t exported properly by the plugin. This required I create some new shortcodes for Hugo and replace the corresponding calls.
- Spoilers. I had only recently added this WP plugin, and only one post was using it so this was straightforward. I created the spoiler shortcode and added some simple jQuery-backed code to toggle the spoiler content. I would have preferred doing this with vanilla JS so as to avoid the jQuery dependency, but I decided to put off learning how to do that for another day.
- MTG Decklists and card links. Individual card links wasn’t an issue - I just generated an anchor as needed, and had to clean up some of the pages that used it. The decklist part was more challenging, as it involved a lot of text parsing. I managed to get it working to a point where the decklists were formatted correctly, but individual cards weren’t linked, before deciding to give up. The main issue is I haven’t figured out how to parse each line to split the card count and the card name, if the card count exists, i.e. “3 Lightning Bolt”. I considered just adding JavaScript to format the contents post-load, but the current behavior will do for now. Maybe I’ll even revisit the Hugo parsing issue later.
Redirects
I wanted to minimize changes in the URLs of older content, so the permalinks for the old posts were kept in place. Another issue was the RSS feed, generated at /index.xml by Hugo, which I wanted at /feed/ so that feed readers don’t need to be updated. A simple redirect in .htaccess was enough to get this done. I’m not much good at regexes, so I had to reference another blog post for this one. The RSS feeds for categories/tags has changed, I think that’s fine.
Automatic Deployment
I referenced another blog post for setting up automatic deployment. The main difference was my host was Webfaction while his was Digital Ocean, which did cause me a bit of trouble when I was trying to set up a Github webhook to automatically deploy on every push. It turns out Webfaction doesn’t allow me to set an env variable in .htaccess to be read by the PHP script (as was in the blog post linked above). It took me a while to figure out this was the issue, so I just gave up on the Github webhook for now and just set a cron job to periodically pull and redeploy the site. I needed the cron job anyway, if I wanted to support future publishing and possibly some form of queueing later on.
Comments
Legacy comments from WP are imported directly into the markdown of each page. Future comments are now handled using Disqus. I already had a Disqus account before, I forgot why I stopped using it. That being said, outsourcing the comments makes a lot of sense.
Limitations
- we lose the site search for now. There are some workarounds, including Google SiteSearch (I believe it has ads) or building a JSON index and searching on the client-side (seems impractical given the number of posts). I believe I’m the only one using the site search anyway, I’ll revisit this at another time.
- the markdown engine allows raw HTML in the content, but if you have any line breaks in between, your structure breaks, so that required some cleanup
Theme
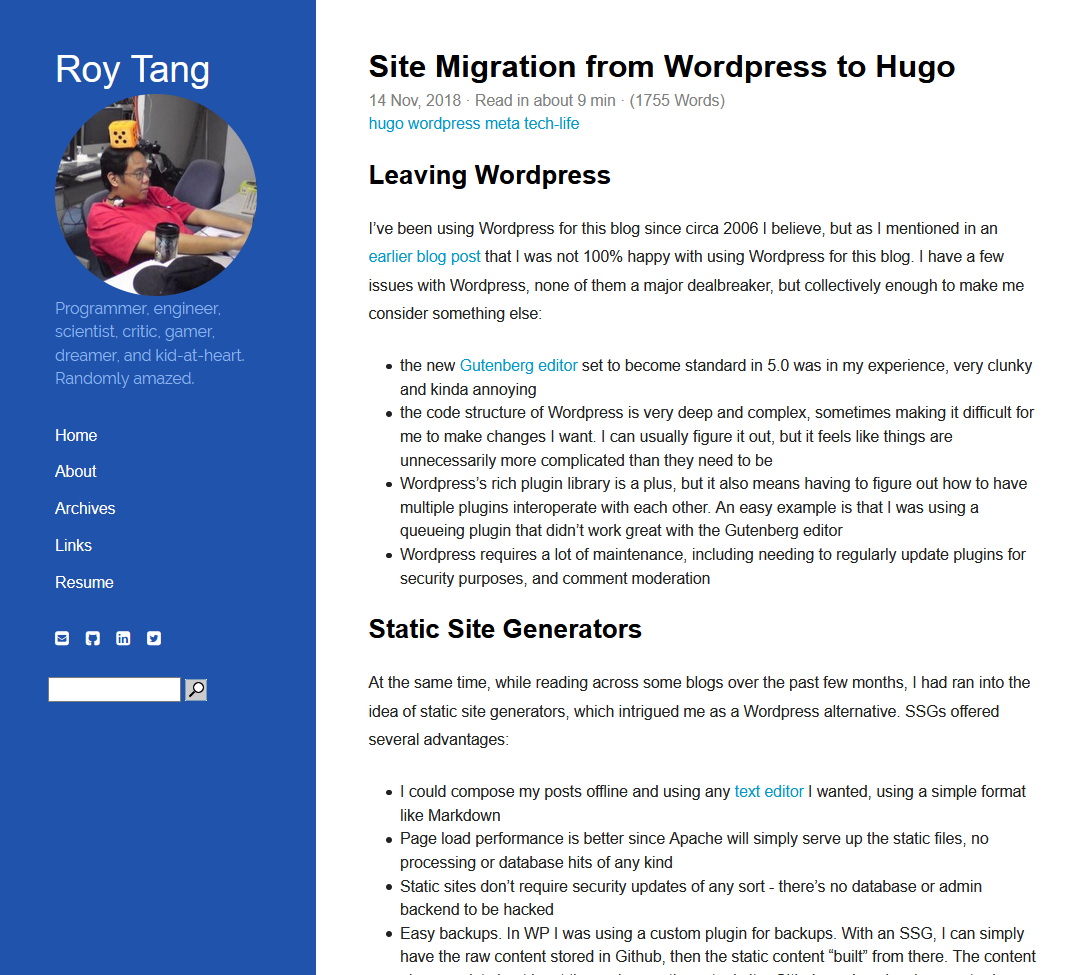
I’m not much of a CSS/site design guy, I’m more a “find an existing theme and tweak it to your liking” guy, so I browsed Hugo’s available themes for a while and settled on Hyde-Y, which I proceeded to modify a bit, adding a picture to the sidebar and so on. It’s simple and clean and straightforward, nothing too fancy. Maybe I’ll revisit the theme later.
For posterity’s sake, a screenshot of the new layout/theme:

Summary
At the end of it, it turned out a bit more effort than I expected. I’ll probably be cleaning up the exported older posts every so often because I’m OC that well. The theming/templating turned out to be a bit more complicated than I expected, but I think it was easier to manage than Wordpress. The last time I tried to use a custom blog engine, I got tired of maintaining and upating it so I switched back to Wordpress, hopefully that doesn’t happen here. Not having to maintain a web interface is a pretty good indicator.
Despite the effort, the great thing is that I did learn a few things, so at the minimum it’s already a win:
- a bit of GoLang
- how to create Github Webhooks
- more .htaccess stuff
- usage of pathlib.Path in Python3 (no more os.glob for me!)
See Also